Why AI Search Does Not Have Rankings Like Google and What That Means for Your Strategy
AI search is probabilistic, not positional. Here is why AI search rankings explained differently changes everything about visibility, measurement, and content strategy in 2026.

SummaryMarketers chasing a "number one ranking" on ChatGPT are asking the wrong question. AI search generates probabilistic, ever-changing outputs, not fixed ranked lists. These systems retrieve candidate content, select relevant passages, and synthesise a natural language answer, so the real goal is retrieval eligibility. Success is measured by citation frequency and share of voice, not position.
Read moreShow less
Marketers keep asking: how do I rank number one on ChatGPT? The question reveals a fundamental misunderstanding of how AI search works. ChatGPT does not have a ranked list. Neither does Perplexity, Claude, or Google AI Mode in the traditional sense. According to SE Ranking research from August 2025, when the same query is run three times in Google AI Mode, results overlap with themselves only 9.2% of the time. That single data point is the clearest possible demonstration of what AI search rankings explained actually means: there is no stable position, only probabilistic output.
The frustration this creates is real. You invest in AI search visibility, run your target queries in ChatGPT, get different results every session, and cannot tell whether your strategy is working or not. You try to apply Google ranking logic to AI search and the framework does not quite fit. You know the two systems are different but nobody has explained the difference in practical terms.
This guide does exactly that. We will explain how Google ranking works, how AI search actually works, why applying the old mental model to AI creates flawed strategies, and what a correct AI search vs traditional SEO framework looks like in practice. You will leave with a clear way to measure, report, and explain LLM search visibility without resorting to positions that do not exist.
How Does Google's Ranking System Actually Work?
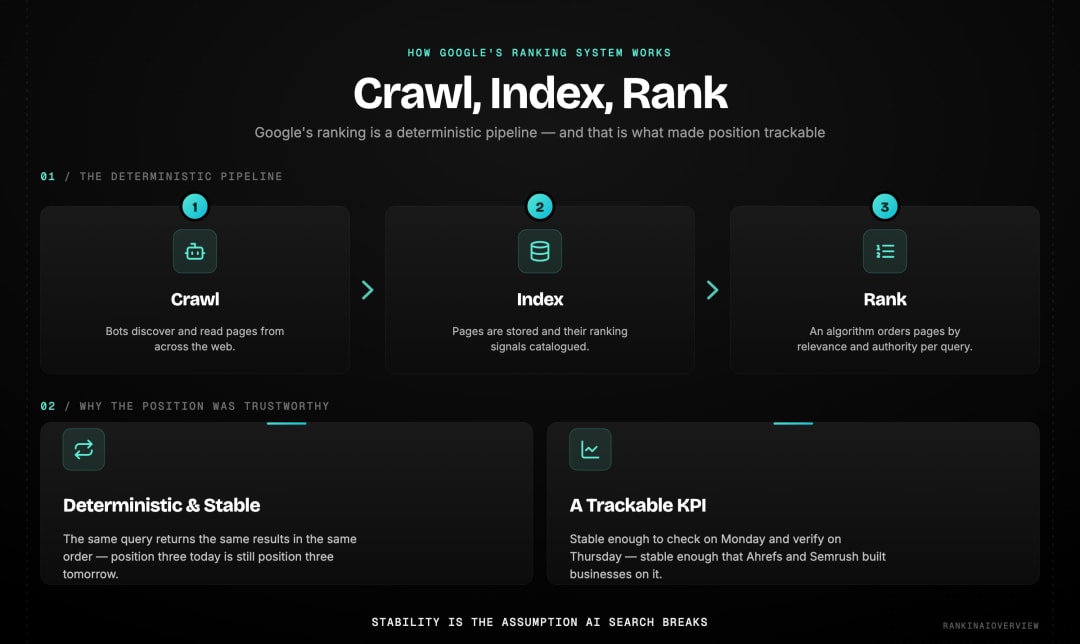
| Google ranking is deterministic. A crawl discovers pages, an index stores them, and a ranking algorithm orders them for a given query. The same query returns the same results in the same order with high consistency. That stability is what made rank tracking commercially viable for two decades. | | :---- |
When Google crawls a page, it reads content, evaluates signals including backlinks, technical health, and E-E-A-T factors, and assigns that page a position for relevant queries. A page in position three today will very likely be in position three tomorrow. Google's own Search documentation confirms this: ranking is based on stable signals evaluated consistently across runs.
This stability is what made AI search rankings explained as a concept confusing. For twenty years, ranking was a measurable, trackable fact. You could check your position on Monday, verify it on Thursday, and present it to a client on Friday. The number meant something precise.
That precision created an entire industry. Ahrefs and Semrush built their businesses on position tracking. Agencies built reporting workflows around monthly ranking reports. The metric worked because the underlying assumption of stability held. That assumption does not transfer to AI search.
How Does AI Search Work Differently From Google?
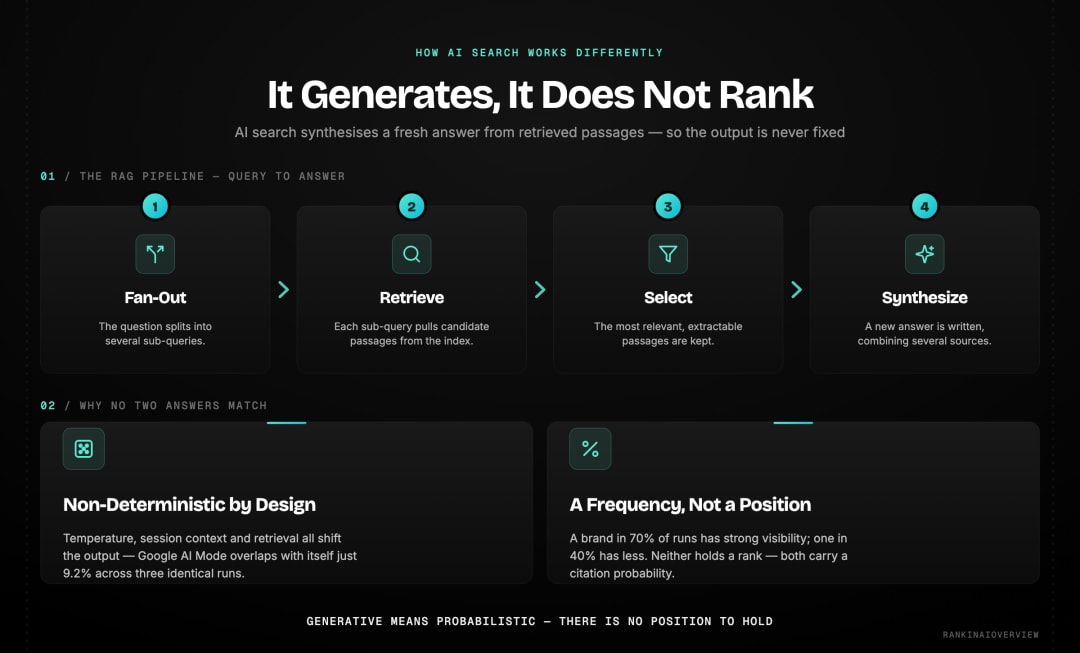
| AI search is generative, not retrieval-based. Instead of returning a ranked list of pages, it synthesises a new piece of text from retrieved content. This synthesis step introduces probability. The same prompt produces different outputs on different runs because the model is generating language, not looking up a fixed answer. | | :---- |
The RAG Pipeline From Query to Answer
Understanding how AI search works vs Google requires understanding Retrieval-Augmented Generation. When a user submits a query to an AI engine, the process unfolds in four stages.
First, query fan-out. The AI does not paste the full prompt into a search index. It breaks the question into multiple sub-queries and searches for each one separately. A question like "what is the best project management tool for remote teams?" might fan out into "project management tools 2026," "remote team software," and "best tools for distributed teams" as separate searches.
Second, retrieval. The AI searches its connected index and retrieves candidate passages from across the web. ChatGPT uses Bing's index. Perplexity uses its own crawler. Google AI Overviews use Google's own index. Each platform retrieves from a different source, which is why AI search rankings explained for one platform does not automatically apply to another.
Third, selection. From the retrieved candidates, the AI selects the most relevant and structurally extractable passages. This is where content format matters: a self-contained, direct-answer paragraph is far more extractable than one that requires surrounding context to make sense.
Fourth, synthesis. The AI generates a natural language answer that draws from multiple selected sources simultaneously. It does not copy and paste. It rewrites and combines. Your page might contribute one sentence to an answer or five. This is what RAG SEO explained looks like in practice: the goal is to be retrieved and selected, not to be ranked in a list.
Why the Same Prompt Returns Different Results Every Time
Large language models are non-deterministic by design. They generate outputs based on statistical probability, not fixed lookups. Temperature settings, session context, retrieval conditions, and even minor prompt variations all affect which output the model generates. SE Ranking's August 2025 research found that Google AI Mode had only 9.2% overlap with itself across three identical queries. Run the same question in the same session twice and you may get meaningfully different answers with different sources cited.
This is not a bug. It is how these systems are designed. The probabilistic nature of generative AI is what allows it to produce nuanced, contextual answers rather than identical copies of stored results. But it completely invalidates the concept of a stable ranking position. A brand that appears in 70% of runs for a given category query has strong LLM search visibility. A brand that appears in 40% has weaker visibility. Neither holds a position. Both have a citation probability.
How Google AI Mode Fits Into This
Google AI Mode is a hybrid. It uses Google's traditional ranking system to select retrieval candidates and then adds a synthesis layer on top. SE Ranking's analysis of AI Mode found that only 14% of URLs cited in AI Mode rank in the traditional Google top 10 for the same query. AI Mode draws from a wider pool than traditional ranking suggests, but traditional organic performance remains the eligibility foundation.
The practical implication: strong traditional SEO is still required as an entry point into AI Mode retrieval. But ranking in the top 10 does not guarantee citation. Content structure, semantic relevance, and entity clarity determine whether a page is selected from the retrieval pool. Understanding AI search vs traditional SEO here requires holding both truths simultaneously: you need organic performance to be eligible, and you need AI-specific signals to be cited.
| “ The future of search is bigger than Google. AI is transforming search into a cross-platform, multi-agent ecosystem where trust, clarity, and real value matter more than tactics or rankings. Aleyda Solis International SEO Consultant and Founder, Orainti Source: Advanced Web Ranking Expert Roundup, December 2025 | | :---- |
What Are the Strategic Implications of Dropping the Rankings Mental Model?
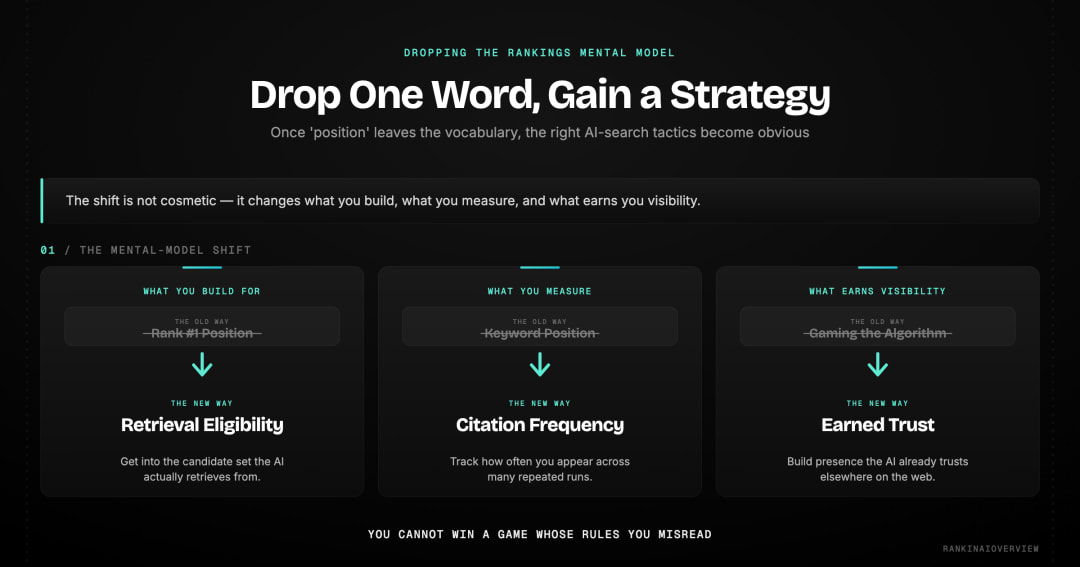
| Once you stop optimising for position and start optimising for retrieval eligibility and trust, the right tactics become obvious. The mental model shift is not cosmetic. It changes what you build, what you measure, and how you report success to clients and leadership. | | :---- |
Stop Optimising for Position. Start Optimising for Retrieval Eligibility.
The question is not "how do I rank number one on ChatGPT?" It is: "am I in the retrieval candidate set for the queries my buyers are asking?" These require different answers.
To be in the retrieval candidate set, your content needs to be crawlable by AI bots, semantically relevant to the sub-queries generated by fan-out, structured for passage-level extraction, and carrying E-E-A-T signals that tell the model this source is credible. None of these requirements involve position. All of them involve content quality and technical clarity.
A concrete example of how AI search works vs Google in practice: a startup with 20 well-structured articles on a specific niche topic can appear in Perplexity answers before it ranks in Google's top 10. Perplexity does not weight domain authority the same way Google does. It weights passage relevance and structural extractability. Understanding RAG SEO explained is what makes this possible to plan for.
Measure Citation Frequency, Not Position

AI search rankings explained as a concept requires replacing position with frequency. Run your 30 to 50 target queries at least 20 times each and measure how often your brand or URL appears. That frequency across many runs is your actual LLM search visibility score. According to Ahrefs research from October 2025, 28.3% of ChatGPT's most cited pages have zero organic visibility in Google. Frequency-based measurement captures this reality. Position-based measurement would show these pages as non-existent.
Weekly measurement across a stable prompt set smooths out the non-deterministic variation and shows real trend movement. Share of voice against your top three competitors gives the relative context that absolute mention rates alone cannot provide.
Trust Is the New Algorithm

AI engines are risk-averse in a way Google is not. Google will serve a new page if it matches keyword signals well enough. AI engines prefer sources they have seen consistently across trusted contexts. SE Ranking research from November 2025 found that domains with profiles on Trustpilot, G2, Capterra, and Yelp have 3x higher chances of being chosen as a source by ChatGPT than domains without such presence. Domains with substantial brand mentions on Quora and Reddit have roughly 4x higher citation probability.
This is what AI search vs traditional SEO means in terms of off-site strategy. For Google, you build backlinks to distribute PageRank. For AI engines, you build entity presence across trusted external contexts. The mechanism is different. The logic, earning trust from sources the system already respects, is the same.
What Does a Good AI Search Strategy Actually Look Like?

| A good AI search strategy builds in three layers simultaneously. Topical authority gets your content into the retrieval pool. Entity recognition gets the model to trust your brand. Off-site signals corroborate your authority externally. All three are required for consistent LLM search visibility over time. | | :---- |
Build topical authority through content clusters. A site that answers every meaningful angle of a topic consistently signals to AI engines that it is the reliable reference point on that subject. Understanding how AI search works vs Google at the architecture level changes content strategy: Google evaluates a page holistically, AI engines evaluate passages individually.
Build entity recognition through Wikipedia presence, Wikidata entries, consistent NAP across directories, and clear structured data on your own pages. This is RAG SEO explained at the brand level: an AI engine needs to resolve your brand name to a known entity before it retrieves your content with confidence. Ambiguity leads to exclusion. Clarity leads to citation.
Build off-site signals through genuine community participation. Contribute to Reddit discussions in your category. Answer questions on Quora with specific, data-backed responses. Earn reviews on platforms relevant to your market. These are the signals that tell AI systems your brand is genuinely authoritative, not just self-asserting authority through your own content.
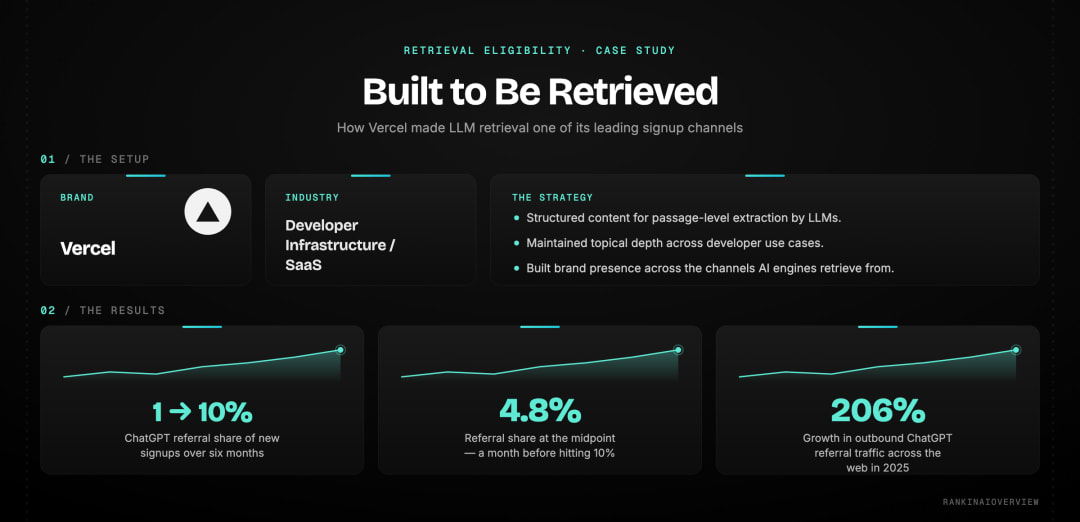
Measure citation frequency and share of voice weekly using tools like Profound, Peec AI, or SE Ranking. Pair this data with branded search volume from Google Search Console. Rising branded search is the downstream signal that confirms AI visibility is translating into real audience behaviour. Vercel documented that ChatGPT referrals grew from 1% to 10% of new signups in six months as their AI search strategy compounded. That kind of measurable downstream impact is what a well-executed LLM search visibility strategy produces.
How Do You Explain This Shift to Clients and Stakeholders?
| The most effective analogy is PR versus a leaderboard. Google ranking is like a leaderboard: your position is visible, stable, and directly competitive. AI search visibility is like PR: your brand appears across trusted editorial contexts, the frequency and quality of those appearances compounds over time, and you cannot reduce it to a single number. | | :---- |
When a client asks "where do we rank in ChatGPT?", the honest answer is that there is no position. There is a citation rate. You can report: "Your brand appeared in 43% of the 50 most relevant queries run in ChatGPT this week, compared to your top competitor at 28%." That is meaningful, comparable, and trend-trackable. A single rank number is not.
Reframe the conversation around business outcomes rather than platform mechanics. Instead of explaining AI search rankings explained in technical terms, connect it to what the client already cares about. Show them that AI-referred traffic converts at higher rates than organic because users are pre-qualified by the AI answer before they arrive. Show them that branded search volume is rising as AI mentions increase. These are outcomes they understand without needing to understand probabilistic retrieval.
| Old Metric | New Metric | What It Measures | | :---- | :---- | :---- | | Keyword ranking position | Citation frequency | How often your brand or URL appears across repeated AI prompts | | Share of top 10 keywords | Share of voice in AI | Your brand mentions vs competitors for a target query set | | Organic traffic volume | AI referral conversion rate | Quality of visitors arriving from AI-driven discovery | | Domain authority | Entity recognition score | Whether AI systems recognise your brand as a known, trusted entity | | Featured snippet capture | Share of synthesis | What proportion of a generated answer is drawn from your content |
Managing expectations around volatility is the final piece. How AI search works vs Google becomes clearest here: Google results are stable enough to report weekly. AI results require trend data across multiple weeks before conclusions are reliable. Set that expectation at the start of any AI visibility programme and you protect your credibility when a single week shows an unexpected dip.
Conclusion
The mental model shift is the strategy. AI search rankings explained is not just an academic distinction. It changes what you build, what you measure, and how you report success. Once you stop thinking about AI search in terms of positions, the right tactics become obvious.
Build topical authority to enter the retrieval pool. Build entity recognition to be trusted by AI systems. Build off-site signals to corroborate your authority externally. Measure citation frequency and share of voice weekly, not individual ranking positions that change with every run. Report against business outcomes, branded search growth, and conversion rates from AI referral traffic.
AI search vs traditional SEO is not a choice between two competing strategies. It is one strategy executed with a different goal. Traditional SEO earns retrieval eligibility. AI-specific optimisation earns citation from that eligible pool. LLM search visibility is what compounds when both are executed consistently over time. For deeper research on how AI engines evaluate brand authority and what drives citation decisions, RANK IN AI OVERVIEW covers this space across its content library.
Frequently asked questions
How does RAG work in SEO?+
RAG stands for Retrieval-Augmented Generation. In SEO terms, it means AI engines search a live web index for relevant content before generating a response, rather than relying solely on training data. Your content needs to be crawlable, semantically relevant, and structurally extractable to be retrieved. [Princeton and Georgia Tech research](https://arxiv.org/abs/2311.09735) found that structured content with specific statistics and clear formatting improves citation probability by 30 to 40 percent over unoptimised content.
How do LLMs retrieve information?+
LLMs retrieve information through a multi-step process. They first expand the user query into multiple sub-queries through fan-out. They then search their connected index for relevant passages from each sub-query. Candidate passages are scored for relevance, authority, and extractability. Selected passages are fed into the generation model, which synthesises a response citing the original sources. [Ahrefs' April 2026 research](https://www.position.digital/blog/ai-seo-statistics/) found that 88% of URLs cited by ChatGPT are retrieved directly from search, not from training data alone.
If there are no rankings how do I know if my AI strategy is working?+
Measure citation frequency, not position. Run your 30 to 50 target queries at least 20 times each, weekly, and track how often your brand or URL appears across those runs. Compare against your top three competitors for share of voice. Pair this with branded search volume in Google Search Console. Rising branded search correlates with improving AI citation and is the clearest downstream signal that your strategy is working.
Does Google's organic ranking still matter for AI Mode?+
Yes, but not in the way most people assume. Traditional Google rankings determine retrieval eligibility: if your page is not in Google's index, it cannot be retrieved by Google AI Mode. But ranking in the top 10 does not guarantee citation. [SE Ranking's AI Mode analysis](https://www.position.digital/blog/ai-seo-statistics/) found that only 14% of AI Mode citations come from pages ranking in the traditional top 10. Strong organic performance is the entry ticket, not the winning condition.
What is the best tool to track AI search visibility?+
The right tool depends on your scale and goals. [Profound](https://www.tryprofound.com) is the most comprehensive for enterprise AI visibility monitoring across ChatGPT, Perplexity, Gemini, and Copilot. [SE Ranking](https://seranking.com) is the best option for agencies that want traditional and AI tracking in one platform. [Peec AI](https://peec.ai) and [Otterly AI](https://otterly.ai) offer accessible mid-market options. For teams not ready to invest in paid tools, manual tracking in ChatGPT and Perplexity across 20 to 30 runs per query weekly is a legitimate starting point. For deeper research on how these tools compare, RANK IN AI OVERVIEW covers this space in detail.
Explore with AI
Share this


