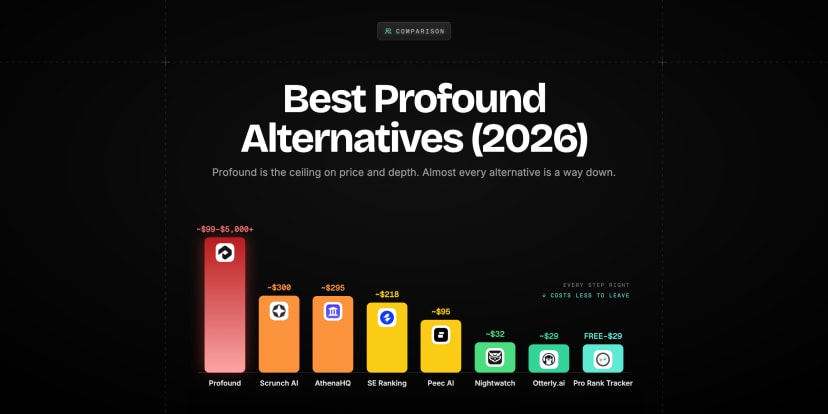
Best AI Rank Trackers (2026): An Honest, Vendor-Neutral Comparison
Every "best AI rank tracker" list is written by a company selling one — and they always win. We're pre-launch with nothing to pump. Here's the neutral comparison, with a real feature matrix.
Key Highlights
-
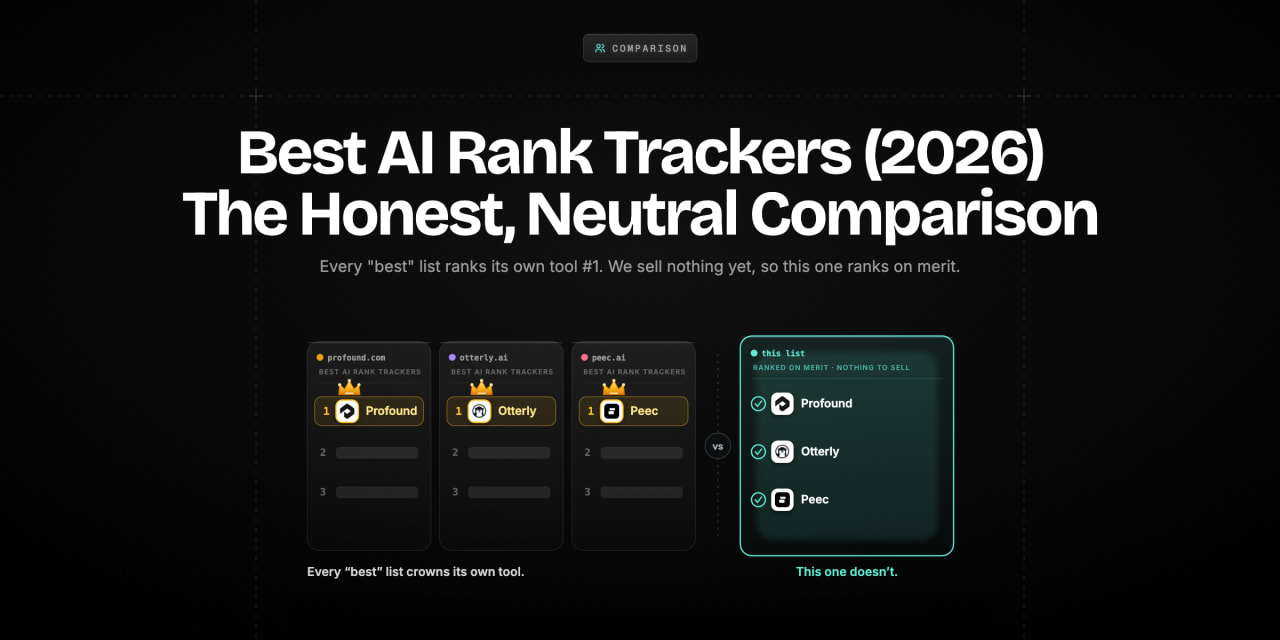
Almost every "best AI rank tracker" roundup ranks the publisher's own tool at number one. We sell nothing yet, so this list ranks on merit, not on who paid for the page
-
The single most important spec is not price or platform count. It is how many times a tool runs each prompt before reporting a number — single-run tools report noise dressed up as a rank
-
There is no stable "rank" in AI search. The honest metric is citation frequency and share of voice across many runs, not a position number
-
This is the only comparison in the category with a true side-by-side feature matrix: platform coverage, citation-vs-mention, multi-run methodology, refresh cadence, free tier, and price in one grid
-
Our methodology is stated in the open, including what we could not independently verify — the opposite of the "we tested everything" claims that no competing list ever backs with evidence
-
Best fit by use case: Profound for enterprise, SE Ranking for agencies running both channels, Otterly for budget UI-level tracking, Peec and Rankscale for mid-market citation work
Search for "best AI rank tracker" and you will find a dozen confident roundups. Read four of them and a pattern appears immediately: the company that publishes the list also sells the tool that wins the list. Rankability ranks Rankability first. A vendor called AI Rank Checker rates itself the top AI rank checker. Tool after tool, the author and the winner are the same company, and not one of them stops to explain why.
That is not a comparison. It is an ad with a table in it.
We can write the version that is not an ad, for one specific and slightly awkward reason: RankInAIOverview is not live yet. We are pre-launch. We have no subscription to defend and no reason to rig the order, so we are the one list in this SERP that gains nothing by lying to you. When our own tool appears later on this page, it appears clearly labelled as pre-launch with a waitlist link and no rank number — because pretending otherwise would make us exactly the thing this article exists to call out.
Here is what the honest version adds that the affiliate roundups do not: a real side-by-side feature matrix instead of scattered prose, a methodology section that tells you plainly what we could and could not verify, and a flat refusal to claim "we tested all of these" when no list in this category has ever shown a single benchmark to prove it. By the end you will know which AI rank tracker fits your team, what these tools genuinely measure, and the one question that separates a credible vendor from a dashboard full of noise.
Why Most "Best AI Rank Tracker" Lists Cannot Be Trusted
Before any feature comparison, understand the structural bias built into almost every roundup in this category. The publisher and the top-ranked tool are usually the same company. That conflict is never disclosed, the testing is never shown, and the feature comparison is never a true matrix. Knowing this is the most useful thing you can take from any AI rank tracker comparison, including the parts of this one you should check for yourself.
There are three problems that nearly every competing list shares, and once you see them you cannot unsee them.
The first is self-dealing. The overwhelming majority of "best AI rank tracker" articles are published by companies that sell an AI rank tracker, and in those articles their own product wins. Sometimes it is dressed in neutral language, sometimes it is openly promotional, but the ranking is decided before the evaluation begins. A list whose conclusion is fixed in advance is not measuring anything.
The second is unproven testing. Almost every roundup claims its authors "tested" the tools. Vanishingly few show a benchmark, an accuracy figure, a prompt set, or a reproducible result. "We tested these" with no evidence is a marketing line, not a methodology, and in a category built on non-deterministic AI outputs it is especially hollow — because testing an AI rank tracker properly means running many prompts many times and reporting the spread, which is exactly the work nobody is showing.
The third is the missing matrix. The information a buyer actually needs — which platforms each tool covers, whether it tracks citations or just brand mentions, how many times it runs each prompt, how often it refreshes, whether there is a free tier, and what it costs — is almost never assembled in one place. It is scattered across paragraphs of prose so you cannot compare two tools at a glance. We fixed that first, below.
The AI Rank Tracker Feature Matrix (2026)
This is the side-by-side grid the category is missing. It compares the six tools we have verified data for across the specifications that actually decide whether a tool is useful: platform coverage, whether it tracks citations or only mentions, whether it aggregates multiple runs per prompt, refresh cadence, free-tier availability, and starting price. Where a value could not be independently confirmed, it is marked as such rather than guessed.
| Tool | Platforms covered | Citation or mention | Multi-run aggregation | Refresh cadence | Free tier | Starting price |
|---|---|---|---|---|---|---|
| Profound | ChatGPT, Perplexity, AI Overviews, Gemini, Copilot, Claude, Grok, DeepSeek | Both (citation + mention) | Yes — multiple iterations per prompt | Configurable | No (paid only) | $99/mo |
| SE Ranking AI Tracker | AI Overviews, ChatGPT, Perplexity | Both | Yes | Weekly within SEO suite | Trial via SE Ranking | Add-on to existing plan |
| Otterly AI | ChatGPT, Perplexity, AI Overviews | Both (UI-level, captures live citations) | Partial — UI-level sampling | Weekly | Limited free tier | $29/mo |
| Rankscale | ChatGPT, Perplexity, Gemini, AI Overviews | Citation-focused (high accuracy) | Yes — citation-detection focus | Not publicly stated | Not publicly stated | Contact for pricing |
| Peec AI | ChatGPT, Perplexity, AI Overviews, Claude, Gemini | Both (share-of-voice focus) | Yes | Weekly | No | $95/mo |
| Ahrefs Brand Radar | AI Overviews, AI Mode, ChatGPT, Perplexity, Gemini, Copilot | Both (large-scale research) | Yes (scale; accuracy questioned in independent tests) | Continuous within Ahrefs | Free Ahrefs account access | $199/mo per AI index |
| RankInAIOverview | Pre-launch — join the waitlist | Citation + mention (planned) | Multi-run by design (our core thesis) | TBD at launch | TBD | Not live yet |
Where pricing or methodology is marked "not publicly stated," the vendor does not publish it and we have not independently tested the tool — so we will not invent a number. That gap is the vendor's to close, not ours to fill with a guess.
What These Tools Actually Measure (and What "Rank" Really Means Here)
AI search has no fixed rankings the way Google does, because large language models are non-deterministic — the same prompt can return different brands on different runs. So a single "rank" number is a snapshot of a probability distribution presented as something more stable than it is. The honest metrics are citation frequency, share of voice, and the trend in both over time, measured across many runs.
Traditional rank tracking works because Google's results are largely deterministic: the same query from the same place at the same time returns the same positions. AI search breaks that assumption at the design level. Large language models generate probabilistic outputs that shift between runs with temperature, session context, and retrieval conditions. You can run an identical prompt twice in the same minute and get two different sets of brands. That is not a bug — it is how generative AI works, and it means a single measurement is close to meaningless on its own. Everything credible in this category is built on aggregation across many runs.
Underneath the marketing, the tools worth paying for measure five things. Brand mention frequency counts how often your brand name appears across a prompt set — the most reliable metric, because it infers no position. Citation rate measures how often your actual URL is linked as a source, which matters most on Perplexity and AI Overviews and is a stronger authority signal than a bare mention. Share of voice compares your mention frequency against competitors across the same prompts, and is the most strategically useful number because a 40% mention rate means little until you learn a rival sits at 75%. Sentiment flags whether mentions are positive, neutral, or negative — directionally useful, but a second layer of approximation on already-probabilistic output, so treat it as a hint, not a measurement. Citation-source tracking identifies which of your specific pages AI engines pull from, which is the most operationally useful of the five because it turns measurement into a content feedback loop. For the full breakdown of each metric and the methodology traps behind them, see our deeper review of whether AI rank tracker tools actually work.
How We Evaluated These Tools (Our Honest Methodology)
The one section every other roundup skips. Here is exactly how this comparison was built, what we relied on, and what we did not independently verify — so you can weight it accordingly. An honest methodology that admits its limits is more useful than a confident "we tested everything" with no evidence behind it.
We judged each tool against six criteria that actually predict usefulness: platform coverage, whether it tracks citations or only mentions, whether it aggregates multiple runs per prompt, refresh cadence, citation-source actionability, and price-fit by team size. Of these, multi-run aggregation matters most — a tool that queries a model once and reports the result is handing you a single sample from a probability distribution and calling it a rank.
Now the part the others leave out. The figures in this article are drawn from vendor documentation and practitioner-community reporting, not from a controlled head-to-head benchmark we ran ourselves. We did not put all six tools on an identical prompt library and measure their accuracy against a ground truth, because no one — including the roundups that claim they did — can establish a stable ground truth for a non-deterministic system without publishing the full method, and none of them have. Where a vendor does not publish a spec, we marked it "not publicly stated" rather than inventing a plausible-looking number. And we have a structural interest to disclose: we are building a tool in this space, which is precisely why we listed ourselves with no rank and no claims we cannot yet support. The honest version of "we tested everything" is "here is what we verified, here is what we did not, and here is how to check the rest yourself."
The Tools, Reviewed
Profound: Best for Enterprise AI Visibility Monitoring
Profound offers the widest platform coverage in the category, spanning ChatGPT, Perplexity, AI Overviews, Gemini, Copilot, Claude, Grok, and DeepSeek. Its share-of-synthesis metric is among the most sophisticated citation measures available, and the platform's real strength is methodology: it runs multiple iterations of each prompt and aggregates the results, directly addressing the non-determinism problem that undermines weaker tools. When you are reporting AI visibility to leadership or clients, aggregated numbers are defensible in a way snapshots never are.
- Coverage: eight AI platforms, the broadest here
- Multi-run aggregation built into the core methodology
- Best suited to established prompt libraries of 50+ queries
Pricing starts at $99/month and scales with prompt volume. Watch-out: for large libraries across many platforms, cost climbs quickly. Good fit for brands where AI visibility is a core strategic initiative; not a fit for teams just dipping a toe into the category.
SE Ranking AI Tracker: Best for Agencies Running Both Channels
SE Ranking is a full SEO platform that bolted on AI visibility tracking as an integrated module. For an agency already running rank tracking, audits, and keyword research inside SE Ranking, adding AI monitoring without adopting a second tool is the most operationally efficient path available. It covers AI Overviews, ChatGPT, and Perplexity alongside traditional organic tracking.
- Cross-channel view: correlate AI citation movement with organic ranking movement in one dashboard
- No context-switching cost for existing SE Ranking teams
- Covers the three platforms most B2B audiences actually use
Pricing is an add-on to your existing plan. Watch-out: AI depth is narrower than a dedicated suite. Good fit for agencies already living in SE Ranking; not a fit if you want the deepest standalone AI visibility tooling.
Otterly AI: Best Budget Entry Point for Citation Tracking
Otterly AI is the most accessible on-ramp at $29/month, and its technical approach sets it apart: rather than hitting model APIs, it monitors AI search platforms as live interfaces, capturing what real users actually see — citation links and source URLs included — instead of what a raw API returns. Those two can diverge meaningfully once platforms layer in personalisation and retrieval.
- UI-level monitoring reflects the real user experience
- Covers ChatGPT, Perplexity, and AI Overviews
- Cheapest credible entry in the category
Watch-out: UI-level tracking is resource-intensive, which caps prompt volume at lower tiers. Good fit for focused prompt sets of 20–50 queries and first-time teams; not a fit for hundreds of queries across many platforms.
Rankscale: Best for Citation Detection Accuracy
Among practitioners who judge these tools on citation-detection reliability, Rankscale is consistently named one of the strongest. It is more focused than the broad visibility suites, prioritising precise citation detection over wide share-of-voice reporting. If your core question is "which of our specific pages are being cited in AI answers, and how often," Rankscale tends to give the most granular answer.
- Citation-detection accuracy is its headline strength
- Covers ChatGPT, Perplexity, Gemini, and AI Overviews
Pricing is not publicly listed, which usually signals enterprise positioning. Watch-out: request a trial and verify methodology before committing — we will not quote a price the vendor does not publish. Good fit for citation-accuracy-first teams; not a fit if you need a broad SOV suite in one place.
Peec AI: Best for Mid-Market Share of Voice Reporting
Peec AI launched in 2025 and quickly gained traction with mid-market teams for clean share-of-voice reporting across ChatGPT, Perplexity, AI Overviews, Claude, and Gemini. At $95/month it sits in a practical middle ground between Otterly's budget entry and Profound's enterprise sophistication, with an interface focused enough that you do not need a dedicated analyst to act on it.
- Five-platform coverage with a share-of-voice focus
- Accessible interface suited to content teams
- Supports multi-client reporting structures
Watch-out: less depth than enterprise tooling, no free tier. Good fit for mid-market content teams and agencies on a mid budget; not a fit for enterprise-scale libraries or budget-only buyers.
Ahrefs Brand Radar: Best for Existing Ahrefs Workflows
Ahrefs entered the category with Brand Radar, tracking mentions and citations across six AI indexes — AI Overviews, AI Mode, ChatGPT, Perplexity, Gemini, and Copilot — backed by a database of over 263 million monthly prompts. For teams already using Ahrefs for keywords and backlinks, it is the most seamless way to add AI citation tracking.
- Six-index coverage at genuine scale
- Seamless for existing Ahrefs users
- Strong for identifying which prompts and topics drive citation in a category
Pricing is $199/month per AI index, or $699/month for all platforms. Watch-out: independent testing has flagged accuracy issues, and per-index pricing adds up fast. Good fit for teams already inside Ahrefs; not a fit where standalone accuracy is the priority.
RankInAIOverview: Pre-Launch (Listed in the Open)
This is our own tool, and the honest thing to do is show it to you with the same scrutiny as the rest — minus the rank we have not earned. RankInAIOverview is not live yet. We are building it around the one principle this whole article keeps returning to: that a single AI "rank" is noise, and credible measurement means running many prompts many times and reporting citation frequency and share of voice with the methodology shown.
- Planned: citation + mention tracking with multi-run aggregation by design
- Planned: a stated, reproducible methodology rather than a "we tested everything" claim
- Not yet available — join the waitlist to be told when it is
We have deliberately given ourselves no rank number and made no spec claims we cannot yet support. If we listed ourselves first, like everyone else does, you would be right to close the tab.
How to Choose the Right AI Rank Tracker for Your Team
There is no single winner, and any list that names one is usually naming its own product. The right tool depends on who you are.
- Enterprise with a core AI-visibility mandate: Profound, for the widest coverage and the most defensible aggregated methodology.
- Agency running SEO and AI monitoring together: SE Ranking, to keep both channels in one dashboard with no second subscription.
- First-time or budget-conscious team: Otterly AI, for credible UI-level tracking at $29/month.
- Mid-market team that reports on share of voice: Peec AI, for clean SOV across five platforms at a workable price.
- Citation accuracy above all: Rankscale, for the most granular answer to "which pages get cited."
- Already living in Ahrefs: Brand Radar, for the most seamless add-on — with the accuracy caveat noted.
Whichever you pick, the decisive question to ask any vendor is the same: how many times do you run each prompt before reporting a number? If the answer is "once," you are buying noise.
Conclusion
Want a single-tool deep dive from this list? Here is our hands-on AI Rank Lab review for 2026.
Almost every "best AI rank tracker" list in this market is written by a company selling one of the tools, and the conclusion is fixed before the comparison begins. We could write the neutral version only because we have nothing to sell you yet — and when our own tool entered this list, it entered with no rank and no claims we cannot support. That is the whole point.
The tools that earn a place are genuinely useful within honest limits. Profound leads for enterprise. SE Ranking fits agencies running both channels. Otterly is the budget entry. Peec and Rankscale serve the mid-market on share of voice and citation accuracy. Ahrefs Brand Radar adds AI coverage for teams already inside its ecosystem. None of them gives you a stable rank, because no honest tool can — what they give you is a trend, and the value is in reading that trend over a quarter rather than a week.
At RANK IN AI OVERVIEW, we track how this landscape evolves and what it means for brand visibility in both Google and AI search. When our own tracker is ready, you will find it held to exactly the standard we have just held everyone else to. Join the waitlist to know when it lands.
Frequently asked questions
What is the best free AI rank tracker?+
The best free option for most small teams is manual testing: run your key prompts in ChatGPT and Perplexity once a week and record what you see. Among paid tools, Otterly AI offers the most accessible entry with a limited free tier. A paid AI rank tracker becomes worth it once you have roughly 30 or more consistent queries to track or need competitor share-of-voice data.
Does Google Search Console show AI Overviews?+
Not separately. Impressions and clicks from AI Overviews are folded into your regular web-search performance in Search Console, with no dedicated AI Overviews breakout. That is exactly why prompt-based AI rank trackers exist — to measure the citation and mention behaviour that GSC does not isolate. The strongest setups combine both signals.
What is the difference between a brand mention and a citation?+
A mention is your brand name appearing in an AI-generated answer. A citation is your specific URL being linked as a source for that answer. A citation is the stronger signal because it means the engine is referencing your actual content, not just recalling your name from training data — and it tells you which page earned the reference.
How often should I run AI visibility reports?+
Weekly. Daily reporting mostly captures the random variation of non-deterministic outputs, which reads as noise rather than insight. Monthly misses real trend movement. A weekly cadence across a stable prompt library smooths out the noise and surfaces genuine change.
Can my brand appear in ChatGPT without ranking on Google?+
Yes. AI engines draw on a mix of parametric memory (what the model absorbed in training) and live retrieval, and neither maps one-to-one onto Google's index. A brand can be cited frequently in AI answers while ranking modestly in traditional search, and vice versa — which is the entire reason AI visibility is now measured as its own discipline.
Is a single AI "rank" number trustworthy?+
No. Any tool that hands you one position number is presenting a single sample from a probability distribution as something more stable than it is. The trustworthy metrics are citation frequency and share of voice aggregated across many runs of many prompts. Before paying for any tool, ask how many iterations it runs per prompt.
Explore with AI
Share this