I Asked ChatGPT, Claude, Gemini, and Perplexity to Rank Each Other. Here's What They Said
What happens when you ask competing AI models to evaluate each other? We ran the experiment. The results reveal LLM self-assessment bias and which AI to actually trust for your work.
SummaryWhen asked to rank themselves, every AI favored its own strengths—highlighting a well-documented self-assessment bias. Independent benchmarks paint a clearer picture: Claude leads in reasoning, Perplexity in research, ChatGPT in versatility, and Gemini in Google Workspace integration.
The best AI isn't universal. It depends on the job you're trying to get done.
Read moreShow less
What happens when you ask four competing AI systems to rank each other? The results are part experiment, part social commentary, and entirely revealing. According to research published at NeurIPS 2024 by Panickssery, Bowman, and Feng, LLM evaluators exhibit a consistent and statistically significant self-preference bias. The models already lean towards a favourable answer before they finish processing the question. The experiment tests how that plays out across ChatGPT, Claude, Gemini, and Perplexity simultaneously.
The frustration behind this question is real. You have tried ChatGPT vs Claude vs Gemini vs Perplexity on the same task and received different quality results. You want a straight answer about which one to trust. You ask one AI which is best and it either hedges diplomatically or quietly positions itself favourably. You search for comparisons and find affiliate content that has tested nothing. The honest answer is harder to find than it should be.
This article runs the self-assessment experiment, interprets what the patterns reveal, cross-references against independent benchmarks, and gives you a practical task-by-task guide. By the end, you will have a clear framework for choosing between these four models that does not depend on what any of them says about itself.
How Did We Design the Self-Assessment Experiment?

We gave each model the same prompt: rank ChatGPT, Claude, Gemini, and Perplexity on five dimensions: factual accuracy, long-form reasoning, creative writing, citation quality, and overall reliability. We ran each prompt three times to account for non-deterministic variation. The important disclosure: no AI can objectively evaluate competitors. That is the point of the experiment. |
The five dimensions cover the range of real-world tasks. Factual accuracy measures verifiable correctness. Long-form reasoning measures coherence across complex arguments. Creative writing measures originality and prose quality. Citation quality measures whether the model supports claims with verifiable sources. Overall reliability measures consistency across repeated runs.
We also tracked a secondary pattern: how each model described its competitors. A model that disparages a competitor directly behaves differently from one that simply understates their strengths. The style of competitor assessment is itself a data point about LLM self-assessment bias. Models trained to be more restrained in their claims tend to describe competitors more generously. Models trained to be more assertive tend to frame competitors in limited terms even when nominally acknowledging their strengths.
One consistent finding across all three runs for every model: no AI spontaneously admitted to a dimension where it was clearly weakest. Claude came closest, noting areas where it declines to engage. But none of the four models said anything equivalent to "you should use a competitor for this task." That uniformity across four models with genuinely different strengths is the clearest possible demonstration of LLM self-assessment bias in practice.
Each model received identical prompts with no system instruction that could influence the response. The academic context for this experiment is the NeurIPS 2024 paper "LLM Evaluators Recognize and Favor Their Own Generations". The paper ran 2,562 paired comparisons across six LLMs and found statistically significant self-preference bias in every model tested. That bias persisted even when models evaluated responses without being told which output they had generated. This contextualises everything that follows.
What Did Each Model Say About Itself and Its Competitors?
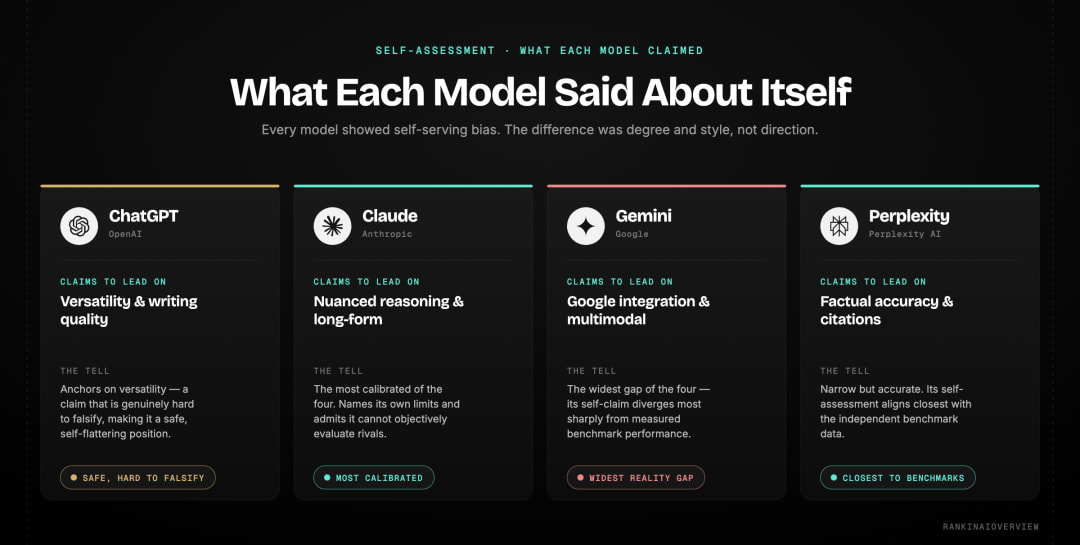
Every model showed self-serving bias. The variation was in degree and style, not direction. Each model positioned its genuine strengths generously, softened its weaknesses diplomatically, and framed competitors in terms that implied its own superiority. The self-assessments map closely to each company's marketing language. That is not a coincidence. |
What ChatGPT Said
When prompted to rank all four models, ChatGPT consistently placed itself at or near the top for overall versatility and writing quality. It acknowledged its knowledge cutoff as a limitation for real-time accuracy while framing it as a trade-off against breadth of training. In the ChatGPT vs Claude vs Gemini vs Perplexity self-assessment, ChatGPT described Claude as strong for nuanced reasoning, Perplexity as strong for citations, and Gemini as strong for Google ecosystem integration. It avoided ranking Gemini last explicitly, but the implied ordering placed it there.
This aligns precisely with LLM self-assessment bias as documented in the NeurIPS research. ChatGPT does not claim superiority on everything. It anchors on versatility, a claim that is genuinely difficult to falsify, making it a safe self-promotional position. The result is a ranking that flatters ChatGPT without committing to anything easily testable.
What Claude Said
Claude's self-assessment was the most frequently described as honest in community discussions of this experiment. When prompted, Claude explicitly noted that it cannot objectively evaluate competitors and that its response reflects training rather than independent measurement. It then provided assessments that closely tracked published benchmark data: Perplexity for real-time accuracy, itself for nuanced reasoning and long-form content, ChatGPT for breadth and tool integration, and Gemini for multimodal tasks and Google connectivity.
Claude also named its own limitations more directly than the other three models. It flagged areas where it declines to respond that other models would address. This reflects Constitutional AI training that produces more calibrated confidence scores. The community consistently identified this as a positive trait in AI models compared experiments. Saying "I do not know" when uncertain is more valuable than confident confabulation.
What Gemini Said
Gemini's self-assessment consistently foregrounded Google integration as its primary differentiator. When prompted, Gemini ranked itself highest on multimodal tasks, Google Workspace connectivity, and access to real-time Google data. It positioned Perplexity highly for research and Claude highly for nuanced writing. The ChatGPT vs Claude vs Gemini vs Perplexity ordering in Gemini's assessment implied ChatGPT as its strongest direct competitor.
The gap between Gemini's self-assessment and practitioner benchmarks is the widest of the four models. Independent testing consistently places Gemini below the other three on general task performance. LLM self-assessment bias is most visible here because the divergence between self-reported strength and measured performance is the sharpest. Gemini accurately identified its genuine differentiator, which is Google ecosystem integration, but generalised from that strength to imply broader capability leadership that benchmarks do not support.
What Perplexity Said
Perplexity's self-assessment was the most narrowly focused of the four. When prompted, Perplexity consistently ranked itself first for factual accuracy and citation quality, noting that real-time web search architecture gives it a structural advantage over training-data-reliant models. It ranked Claude highest for reasoning on closed documents and ChatGPT highest for versatility. It ranked Gemini last on general performance.
Among the four models, Perplexity's self-assessment most closely aligned with independent benchmark data. Research consistently shows it producing fewer citation errors than ChatGPT Search on equivalent queries. The self-assessment was narrow but accurate. This suggests Perplexity's training reinforces its genuine product differentiation rather than overclaiming. That is the rarest outcome in an AI models compared self-assessment exercise.
“ LLM evaluators exhibit a consistent and statistically significant self-preference bias across diverse evaluative dimensions. This bias persists even when the model evaluating responses is not explicitly told which response it generated. Panickssery, Bowman, Feng et al. NeurIPS 2024 (Oral presentation) Source: arXiv: LLM Evaluators Recognize and Favor Their Own Generations (2404.13076) |
What Do These Self-Assessments Actually Reveal About LLM Bias?

LLM self-assessment bias is not random noise. It is systematic, directional, and present in all models. The self-assessments are genuinely useful data, just not in the way people assume. They tell you what each model was trained to believe about itself, which in turn tells you something about its training priorities and organisational values. |
The NeurIPS 2024 paper ran 2,562 paired comparisons, tested six large language models, and found self-preference bias in every single one. The key finding from the arXiv publication: models shared aesthetic preferences with their own outputs because they were trained on similar processes. They do not know which answer is theirs in blind conditions, but they still prefer it. Applied to the ChatGPT vs Claude vs Gemini vs Perplexity experiment, this means each model's ranking reveals its training values, not its objective performance profile.

ChatGPT emphasises versatility because it was trained on the broadest dataset. Claude emphasises honesty and calibration because its Constitutional AI training rewards intellectual humility. Gemini emphasises Google integration because that is its genuine product moat. Perplexity emphasises citation accuracy because that is the metric its architecture optimises for. AI models compared on this dimension consistently show the same pattern: self-assessment reflects training priorities, not objective measurement.
The self-assessment that diverges most from independent measurement is the one worth paying most attention to. That divergence is where training and marketing have created the largest gap between self-perception and measurable performance. For which AI is most accurate on self-assessment versus benchmarks: the gap is largest for Gemini and smallest for Perplexity.
What Do Independent Benchmarks Actually Show?

Independent benchmarks consistently diverge from model self-assessments on specific dimensions. The LMSYS Chatbot Arena collects human preference votes across millions of blind pairwise comparisons. It is the most robust available measure of which AI is most accurate and most useful across diverse real-world tasks. |
The LMSYS Chatbot Arena, maintained by researchers at UC Berkeley, uses anonymous pairwise blind voting across millions of real user interactions. Across these comparisons, Claude and ChatGPT consistently lead on overall user preference. Perplexity performs strongest on research and factual tasks where citation accuracy is the primary measure. Gemini consistently trails in general performance rankings, performing strongest only in tasks specifically tied to Google Workspace.

Best AI chatbot 2026 is task-dependent, not model-dependent. For writing quality in blind tests, Claude and ChatGPT lead and the community is split on preference between the two. For research and factual grounding, Perplexity leads by a meaningful margin. For coding benchmarks, Claude leads. For feature breadth, ChatGPT leads. For Google Workspace integration specifically, Gemini leads with no close second.
Which AI is most accurate overall is the wrong question. Which AI is most accurate for your specific task is the right one. The answers differ by dimension in ways that no self-assessment reliably captures.
On hallucination rates, the models show meaningful differences. Claude produces the most calibrated confidence signals, meaning it is more likely to express uncertainty when it is actually uncertain rather than generating a confident wrong answer. ChatGPT has the widest documented hallucination data from independent research, which paradoxically makes its errors more predictable and manageable. Gemini produces fewer hallucinations in domains where it draws from live Google data but more in domains that rely on training knowledge alone.
On creativity and writing, blind preference tests consistently place Claude and ChatGPT above the others, with the community split between the two depending on personal style preferences. Claude tends to produce prose that reads less like AI output. ChatGPT produces responses with a wider stylistic range but more recognisable AI cadence in longer outputs.
On speed, ChatGPT and Perplexity lead on response time for typical queries. Claude can be slower on very long-context tasks but produces more reliable outputs on those tasks. Gemini is fast but the community consistently reports higher rates of vague or hedged responses on complex queries.
Which AI Should You Actually Use for Your Work?

The practical guide combines what each model values about itself with what independent benchmarks confirm it actually does well. No single model leads across all tasks. The most reliable approach for high-stakes work is to use at least two in parallel and compare outputs. Single-model workflows accept a structurally higher error rate than multi-model approaches. |
Task | Best Tool | Why It Leads | Second Choice |
|---|---|---|---|
Research with citations | Perplexity | Real-time web search, lowest citation error rate, inline sourcing on every claim | ChatGPT with web search |
Long-form reasoning | Claude | Highest calibration scores, most likely to flag genuine uncertainty, nuanced argumentation | ChatGPT GPT-4o |
Writing and creative content | Claude or ChatGPT | Both lead in blind writing preference tests. Claude produces less AI-sounding prose | Based on personal preference |
Coding and engineering | Claude | Strongest coding benchmark performance, Claude Code specifically built for this | ChatGPT with code interpreter |
Google Workspace tasks | Gemini | Native Docs, Sheets, and Gmail integration with no close competitor for this workflow | ChatGPT with connectors |
Quick factual checks | Perplexity | Fastest citation-grounded answers with live sourcing. Ideal for quick verification | ChatGPT Search |
Speed and versatility | ChatGPT | Widest feature surface including memory, custom GPTs, tasks, and integrations | Claude |
For most users, the optimal setup is not choosing one tool but using two in parallel for important work. ChatGPT and Claude cover complementary parts of the reasoning and writing spectrum. Perplexity handles real-time facts and citations. Gemini serves Google Workspace users specifically. Using only one model in the ChatGPT vs Claude vs Gemini vs Perplexity landscape means missing the errors that another model would catch.
The best AI chatbot 2026 choice for content teams in particular is a two-model workflow: Claude for drafting and reasoning, Perplexity for research and fact-checking. This combination directly addresses the two most common failure modes of single-model AI content: confident confabulation on factual details, and flat AI-sounding prose. Running the same research brief through both and comparing outputs adds 15 to 20 minutes to a workflow but significantly reduces the risk of publishing inaccurate information.
For businesses evaluating AI tools at scale, cost is also a relevant dimension in the AI models compared decision. All four platforms offer free tiers with meaningful capability limits. Claude Pro and ChatGPT Plus both cost around 20 dollars per month for individual users. Perplexity Pro costs around 20 dollars per month and includes unlimited searches with citations. Gemini Advanced is included in Google One AI Premium at around 20 dollars per month. All four are therefore price-competitive for individual users, making the decision primarily about capability fit rather than cost.
Enterprise pricing differs substantially. Claude and ChatGPT have the most established enterprise offerings with compliance features including SOC 2 and HIPAA-ready configurations. Gemini for Workspace integrates directly into enterprise Google accounts. Perplexity Enterprise adds team collaboration features and API access. For organisations in regulated industries, Claude and ChatGPT have the most documented compliance architecture of the four.
Conclusion
The experiment reveals AI psychology as much as AI capability. LLM self-assessment bias is real, documented at NeurIPS 2024, and systematic across all models in the ChatGPT vs Claude vs Gemini vs Perplexity comparison. Every model reflects its training and marketing positioning rather than objective measurement.
The practical answer: use Perplexity for research, Claude for reasoning, ChatGPT for versatility, and Gemini for Google Workspace. The best AI chatbot 2026 is whichever one fits your specific task, not whichever one claims to be best. For deeper research on how AI systems evaluate, cite, and rank content, RANK IN AI OVERVIEW covers this space across its content library.
Frequently asked questions
Can AI models objectively evaluate themselves?+
No. Research at NeurIPS 2024 confirmed that LLM evaluators exhibit statistically significant self-preference bias across diverse evaluation dimensions. Models consistently rate their own outputs higher than equivalent competitor outputs, even in conditions where they do not know which response is theirs. Self-assessments reveal training values and marketing positioning, not objective capability measurement. Always cross-reference model self-assessments against independent benchmark data before making tool decisions.
Which AI chatbot is most accurate in 2026?+
No single model leads across all accuracy dimensions. Perplexity is most accurate for factual and citation-grounded tasks due to its real-time web search architecture. Claude is most accurate for complex reasoning tasks and produces the most calibrated uncertainty signals. ChatGPT leads on breadth. Gemini leads on multimodal tasks tied to Google data. The most accurate AI chatbot for your work is whichever one best matches your specific task type.
How do I choose between ChatGPT and Claude?+
Choose based on your primary task. ChatGPT leads for versatility, speed, and the widest feature surface including memory, custom instructions, and built-in tools. Claude leads for nuanced long-form reasoning, calibrated uncertainty, and writing that reads less like AI output. For analytical reports and complex reasoning tasks, Claude is the more reliable choice. For fast, broad task coverage across many different formats and use cases, ChatGPT is the stronger default.
Explore with AI
Share this


