What Does 'Ranking' Mean in AI Search? Redefining Visibility for the GEO Era
In AI search, there are no ranked lists. So what does 'ranking' actually mean and how do you measure success? This guide redefines AI search visibility for the GEO era.

SummaryAI search has no fixed rankings. Platforms like ChatGPT and Perplexity work on citation probability, where brands appear based on how often AI systems trust and use their content. Modern GEO success is measured through metrics like citation frequency, share of synthesis, entity presence, and share of voice shifting optimization from chasing positions to building trusted authority.
Read moreShow less
When you type a query into ChatGPT or Perplexity, there is no page one. No position three. No rank tracker that tells you where you stood yesterday. What is ranking in AI search is one of the most misunderstood questions in modern marketing. According to original GEO research from Princeton, Georgia Tech, and the Allen Institute of AI, the visibility metrics that govern brand presence in generative engine outputs share almost no structural similarity with traditional ranking position. The industry needs a new vocabulary to replace the one it inherited from 1998.
The frustration is real. You run your target queries in ChatGPT, get different results every time, and cannot tell whether your content strategy is working or not. Traditional generative engine optimization frameworks feel like SEO with different vocabulary rather than a genuinely new discipline. And yet GEO ranking standards actually do exist. They are just built on a different model of how search works.
This guide cuts straight to what matters. We will explain exactly why AI search has no rankings, define the five GEO optimization metrics that replace position as success measures, build out the vocabulary you need to work in this space, and give you a practical measurement framework. No padding. Every section earns its place.
Why Did Traditional Rankings Work So Reliably?
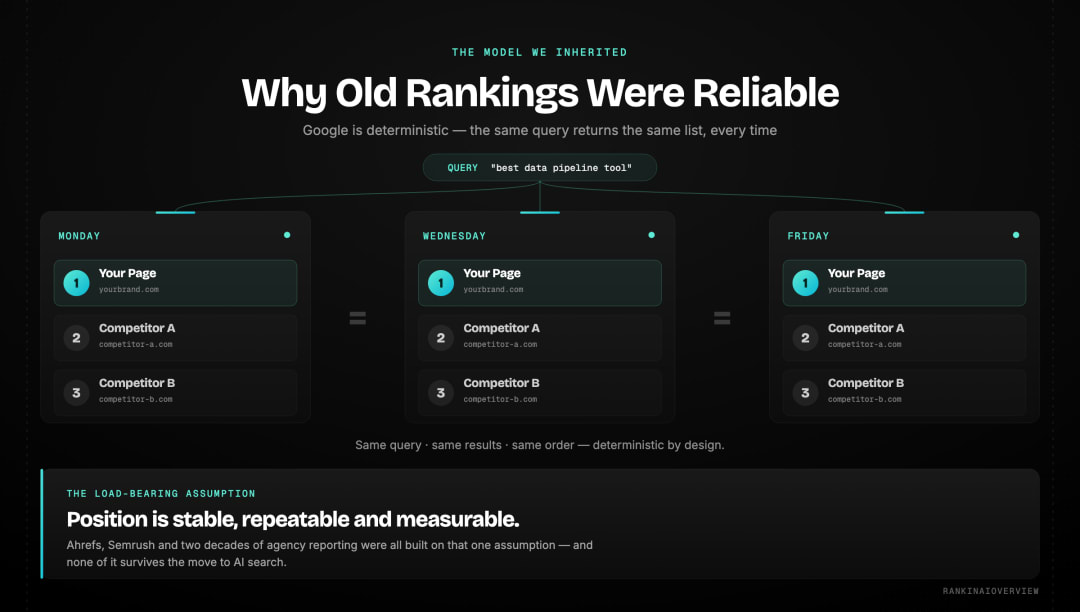
Google search is deterministic. The same query, entered from the same location at roughly the same time, returns the same results in the same order. Position one stays position one from Monday to Thursday. This stability made rank tracking commercially viable and turned keyword position into the defining KPI of a two-decade industry.
The consequence: Ahrefs and Semrush built multi-billion dollar businesses on monitoring those positions. Agencies built monthly reporting models around them. The metric worked because the underlying assumption, that position is stable and measurable, was valid. That assumption does not hold in AI search at all.
How Does AI Search Actually Work?

AI search runs on Retrieval-Augmented Generation, or RAG. When a user asks a question, the system does not simply return the top-ranked page. It breaks the question into multiple sub-queries through a process called query fan-out, retrieves relevant passages from across its index for each one, then uses a large language model to synthesize a single answer from the combined results.
Here is a concrete example. A query like "what is the best data pipeline tool for SaaS startups?" might fan out into sub-queries like "data pipeline tools 2026," "ETL tools SaaS," and "best tools for data integration small teams." The AI retrieves content for each sub-query separately, selects the most authoritative and structurally extractable passages, and generates a synthesized response that may cite two to five sources. Your page might rank first for the original query and still not be the source the AI chooses for any of the sub-queries.
The generation step is also probabilistic. Large language models produce outputs based on statistical patterns, not fixed lookups. Temperature settings, retrieval conditions, session context, and even prompt phrasing all affect which sources get cited. Run the same query twice in the same session and you can receive meaningfully different responses. This is not a bug. It is how these systems are designed.
Do AI Search Engines Actually Have Rankings?

The clearest answer to this question comes from primary research. Rand Fishkin at SparkToro ran 2,961 prompts across ChatGPT, Claude, and Google AI using 600 volunteers submitting identical queries. Fewer than 1 in 100 runs returned the same list of brands. Fewer than 1 in 1,000 returned the same list in the same order. Do AI search engines have rankings? No. They have citation probability distributions. A brand might surface in 70 percent of runs for a given query and a competitor in 40 percent. That difference is meaningful and measurable. But it is not a position. It is a frequency. See the full methodology.
This distinction changes everything downstream. If do AI search engines have rankings is the wrong question, then the wrong tactics follow from it. Teams chasing AI rank numbers optimize for prompts where they appear instead of building the structural authority that produces consistent citation probability. They report single-run results as meaningful data instead of aggregating across many runs. They chase a metric that does not exist instead of building one that does.
“ Any tool that gives a 'ranking position in AI' is full of baloney. Rand Fishkin CEO and Co-founder, SparkToro Source: Near Memo Podcast, February 2026 |
|---|
What GEO Optimization Metrics Replace Traditional Rankings?

Generative engine optimization has converged on five AI search visibility metrics that collectively describe brand presence in AI-generated answers. Each one captures a different dimension of what is ranking in AI search.
Citation Frequency

Citation frequency is how often your brand or URL appears across a defined set of prompts, measured across many runs. It is the most foundational GEO optimization metric because it does not require inferring position. It counts appearances and reports an average rate.
The sample size requirement is non-negotiable. A single run is statistically meaningless. Princeton and Georgia Tech GEO research found that top optimization methods improve AI visibility by 30 to 40 percent, but measuring that improvement requires at least 20 to 60 runs per prompt before a frequency score means anything. A practical example: 1840 and Co., a remote staffing brand, started at zero citation frequency across their target prompts. After restructuring content around the patterns Profound showed were being cited in their category, they reached 11 percent citation frequency and broke into the top five brands in remote staffing AI answers. The movement was invisible until they measured it properly.
Share of Synthesis

Share of synthesis SEO goes deeper than counting citations. It measures what percentage of a generated answer is actually drawn from your content. Your URL might appear as a cited source while contributing only one sentence to the response. Or your content might account for 40 percent of a generated answer without a citation link. Profound named and tracks this metric across ChatGPT, Perplexity, Google AI Overviews, Gemini, Copilot, Claude, and Grok. It is the most direct measure of how much AI engines actually rely on your content. Airbyte used share of synthesis SEO tracking to identify exactly where their content was contributing to AI answers, then restructured content for direct-answer extraction. Within one week, ChatGPT visibility tripled. Within the same program, a 100K dollar deal closed from a ChatGPT referral, providing verifiable downstream business impact.
Entity Presence

Entity presence measures whether AI models recognize your brand as a known, trusted entity in their knowledge structure. This is distinct from being crawled as a URL. When your brand appears consistently across authoritative third-party sources, Wikipedia entries, Wikidata records, G2 profiles, and industry publications, AI engines build an entity map that connects your brand to a specific category and use case.
A concrete example: InSinkErator deployed Schema App's Entity Linking across their site, connecting brand entities to Wikipedia, Wikidata, and Google's Knowledge Graph. The result was a 69 percent increase in clicks for non-branded queries and measurable improvement in AI-generated brand descriptions across platforms. The content had not changed. The entity clarity had. Google's structured data documentation confirms that entity understanding is central to how its AI systems evaluate content credibility.
Share of Voice

Share of voice is the competitive version of citation frequency. It asks how often your brand appears relative to competitors across the same prompt set. A 40 percent citation frequency sounds strong until you discover your primary competitor sits at 70 percent.
HubSpot's experience from late 2024 to early 2025 illustrates why this metric matters more than absolute numbers. Organic traffic collapsed 70 percent as AI Overviews absorbed clicks. But HubSpot's AI share of voice held at 35.3 percent across their category, and they remained cited in nearly every AI-generated response for CRM and marketing software queries. Traffic dropped. AI dominance did not. That distinction, which share of voice captures and citation frequency alone does not, is what separates GEO ranking standards from traditional rank metrics.
Mention Sentiment

Mention sentiment tracks the tone and framing of how your brand appears in AI answers. A brand appearing in 60 percent of category prompts looks healthy until the breakdown reveals that 40 percent of those appearances use cautious language. AI phrasing like "Brand X may be suitable for small teams but lacks enterprise features compared to Brand Y" actively suppresses purchase consideration even when the brand is technically present.
Research from Visiblie tracking across 200 brands found that the average brand receives endorsement framing in only 28 percent of category prompts where it appears. Brands that systematically tracked and addressed the sources driving cautious sentiment shifted their endorsement rate by 15 percentage points within 90 days. The fix was always the same: trace the cautious framing back to its source, whether a G2 review, a competitor comparison page, or an outdated press article, and replace it with content that addresses the perception directly. Among the five AI ranking metrics 2026 frameworks identify, mention sentiment is the most actionable for brand reputation work. Source: Visiblie AI Brand Sentiment Tracking.
What Is the Core Vocabulary of Generative Engine Optimization?
The GEO field is developing faster than its terminology is standardizing. These five terms will appear consistently in vendor conversations, industry coverage, and client discussions. Understanding them precisely prevents confusion.
Term | Plain-Language Definition | Why It Matters for GEO Ranking Standards |
|---|---|---|
Generative Engine Optimization (GEO) | Structuring and distributing content so AI-powered engines cite it when generating answers | Umbrella discipline replacing keyword-ranking as the central optimization goal |
Answer Engine Optimization (AEO) | Optimizing content to appear directly in AI-generated answer boxes | Tactical subset of GEO focused on FAQ and direct-answer formats |
Share of Synthesis | Percentage of an AI-generated answer drawn from your content across many runs | Most direct measure of how heavily AI engines rely on your specific content |
AI Citation Rate | How often your URL appears as a cited source link in AI responses | Measures content-level authority, not just training data brand awareness |
Prompt Universe | The 30 to 100 queries you consistently track to measure AI visibility | A poor prompt set makes all GEO optimization metrics meaningless regardless of tools used |
One clarification worth making: GEO, AEO, LLMO, and AI SEO all describe overlapping practices. The industry has not settled on a single term. They all describe the same goal. Get your content cited by AI engines when relevant buyers are asking questions.
Why Does Trying to 'Rank' in AI Search Lead to the Wrong Strategy?
The ranking frame produces three specific failure modes. First, it creates expectations that cannot be met. When you report a position number for AI search and it changes the following week without any content change on your end, credibility erodes. Teams abandon GEO optimization before it has time to compound.
Second, it generates wrong tactics. Teams that optimize for 'ranking' in AI search tend to focus on branded prompts where their company already appears, rather than category-level queries where the real discovery opportunity lives. They treat single-run appearances as wins rather than building citation frequency across many runs. They optimize for being mentioned rather than for being cited substantively.
Third, it misframes the competition. GEO ranking standards are not zero-sum in the way SERP position is. An AI can cite multiple sources in one response. Your content and a competitor's can both contribute to the same answer. The goal is not to displace anyone from position one. The goal is to become a source AI engines consistently want to include. That requires building trust over time, not finding the right keyword to insert into a prompt.
“ Visibility, not raw referral traffic, is becoming the main currency of organic search. Kevin Indig Growth Advisor and Founder, The Growth Memo Source: Webflow Blog, October 2025 |
|---|
What Does a Practical AI Visibility Measurement Framework Look Like?

Start with your prompt universe. Identify 30 to 50 queries that reflect how your target buyers research your category in natural language, not branded terms. Use Google's People Also Ask, Reddit threads, and Quora questions to find the exact phrasing real buyers use. A prompt set built around branded queries flatters your visibility without reflecting actual discovery moments.
Run each prompt at least 20 times before calculating any GEO optimization metric. This is the most commonly skipped step and the one that produces the most misleading data when skipped. Tools like
Tools like Profound, Peec AI, Otterly AI, and SE Ranking automate this aggregation. For manual tracking, build a spreadsheet that logs 20 to 30 runs per prompt before averaging. Weekly cadence smooths out non-deterministic variation. Daily cadence generates noise. Monthly cadence misses real trend movement.
Pair your AI search visibility metrics with two traditional signals. Branded search volume in
Pair your AI search visibility metrics with two traditional signals. Branded search volume in Google Search Console tends to rise when AI citation frequency improves, as users who encounter your brand in an AI answer follow up with a direct search. That correlation is your clearest evidence that AI visibility translates into real business activity. Second, segment GA4 by AI referral source and compare conversion rates against your organic baseline. AI-referred visitors typically convert at significantly higher rates because an AI has already pre-screened your brand for them. If that is true in your data, you have a clear financial case for continuing to invest in generative engine optimization.
One honest note on timelines. Content changes like answer-first formatting, FAQ sections, and schema markup show measurable citation frequency improvements within four to eight weeks. Building entity presence through off-site mentions, Wikipedia entries, and review platform profiles is a three to six month program. Set expectations accordingly and report AI ranking metrics 2026 frameworks recommend alongside traditional organic data, never in isolation. AI ranking metrics 2026 reward consistency over short-term optimization bursts. The brands building citation authority now will be the brands AI engines confidently cite throughout the rest of this decade.
Conclusion
What is ranking in AI search? It is not a position. It is a status. You are either a trusted, recognized entity that AI engines encounter consistently enough across authoritative sources to cite with confidence, or you are not. Do AI search engines have rankings in the traditional sense? No. They have citation probability, and that probability is what generative engine optimization is designed to build.
The five GEO optimization metrics, citation frequency, share of synthesis SEO, entity presence, share of voice, and mention sentiment, give you a complete and measurable picture of that probability. Of these, share of synthesis SEO is the most underused. Most teams track mentions but not contribution. The AI ranking metrics 2026 requires are all trackable today, with or without paid tools, as long as you run enough prompt iterations to produce statistically meaningful data.
Stop asking how you rank. Start asking how often AI engines trust your content enough to cite it when relevant buyers are asking the questions that matter to your business. What is ranking in AI search, ultimately, is that question answered consistently in your favor. That reframe, from position to trust, from ranking to citation probability, is the shift that GEO ranking standards are built around. For deeper research on how AI engines evaluate brand authority and what drives citation behavior across categories, RANK IN AI OVERVIEW covers this space in depth across its content library.
Frequently asked questions
How do LLMs pick sources?+
LLMs pick sources through two stages. At the retrieval stage, they favor pages that are crawlable, indexed, semantically relevant to the fan-out sub-queries, and structured for direct-answer extraction. At the generation stage, they weight sources by E-E-A-T signals, entity clarity, content freshness, and how self-contained each passage is. [Princeton and Georgia Tech GEO research](https://arxiv.org/abs/2311.09735) found that adding specific statistics, authoritative quotations, and clear structure increases citation probability by 30 to 40 percent. There is no submission process or special access. Strong SEO foundations and GEO-specific content formatting are the inputs.
What is GEO and how is it different from SEO?+
SEO optimizes for position on a ranked list of links. Generative engine optimization optimizes for inclusion in a synthesized response that may never produce a clickable link at all. The shared foundation is content quality, technical health, and E-E-A-T signals. The GEO-specific layer adds direct-answer formatting, entity clarity, off-site presence building, and a measurement framework built on citation frequency and share of synthesis rather than keyword position.
Can you track AI visibility without paid tools?+
Yes. Manual tracking in [ChatGPT](https://chat.openai.com) and [Perplexity](https://www.perplexity.ai) covers the basics at zero cost. Run each target query 20 to 30 times, record which brands appear and how often, log results weekly in a spreadsheet, and pair with branded search data from [Google Search Console](https://search.google.com/search-console/about). Paid platforms add scale, competitor tracking, sentiment analysis, and automated aggregation. They justify their cost once your prompt universe exceeds 50 queries or you need to report AI search visibility metrics to clients consistently.
Does traditional rank tracking still have value in the GEO era?+
Yes, as an eligibility check rather than a success metric. Research consistently shows that 70 to 80 percent of AI-cited pages rank in the top 10 organic results for related queries. Maintaining strong rankings keeps your content inside the retrieval pool AI engines draw from. Monitor your top 20 keyword positions monthly as a foundation check. Do AI search engines have rankings? No. But traditional rankings determine whether AI engines can find you at all. GEO ranking standards measure citation frequency, share of synthesis, and share of voice. Traditional ranking tells you whether you are eligible for consideration. It no longer tells you whether you are winning.
Explore with AI
Share this


